



製品特徴
現代で最も重要な作業を高速化
NVIDIA A100 TensorコアGPUによる、あらゆる規模での前例のない高速化を実現し、世界で最も困難な計算にAI、データ分析、 HPCで挑むことができます。数千単位のGPUに効果的に拡張できるほか、NVIDIAマルチインスタンスGPU(MIG)テクノロジーを利用し、7個のGPUインスタンスに分割することで、あらゆるサイズのワークロードを加速することができます。また、第3世代のTensorコアでは、多様なワークロードであらゆる精度が高速化され、洞察を得るまでの時間と製品を市場に届けるまでの時間が短縮されます。
ディープラーニングトレーニング
NVIDIA A100の第3世代TensorコアとTensor Float(TF32)精度を利用することで、前世代と比較して最大20倍のパフォーマンスがコードを変更することなく得られ、Automatic Mixed Precision(AMP)とFP16の活用でさらに2倍の高速化が可能になります。第3世代 NVIDIA® NVLink®、NVIDIA NVSwitch™、PCI Gen4、NVIDIA Mellanox InfiniBand、NVIDIA Magnum IOソフトウェアSDKの組み合わせで、数千単位のA100 GPUまで拡張できます。拡張することで、BERTのような大型のAIモデルを1,024個のA100からなるクラスターでわずか37分でトレーニングできます。
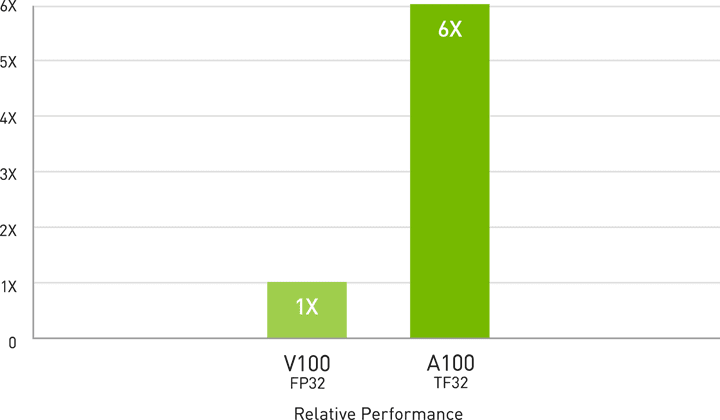
AIトレーニング向けのTF32を使用して、設定不要で最大6倍高速な性能を実現
BERT pre-training throughput using Pytorch, including (2/3) Phase 1 and (1/3) Phase 2 | Phase 1 Seq Len = 128, Phase 2 Seq Len = 512; V100: NVIDIA DGX-1™ server with 8x V100 using FP32 precision; A100: DGX A100 Server with 8x A100 using TF32 precision.
ディープラーニング推論
A100には、推論ワークロードを最適化する画期的な新機能が導入されています。その汎用性には前例がなく、FP32からFP16、INT8、INT4まで、あらゆる精度を加速します。マルチインスタンスGPU(MIG)テクノロジーでは、1個のA100 GPUで複数のAIモデルを同時に運用できるため、計算リソースの使用を最適化できます。また、A100の数々の推論高速化は、スパース行列演算機能によってさらに2倍の性能を発揮します。
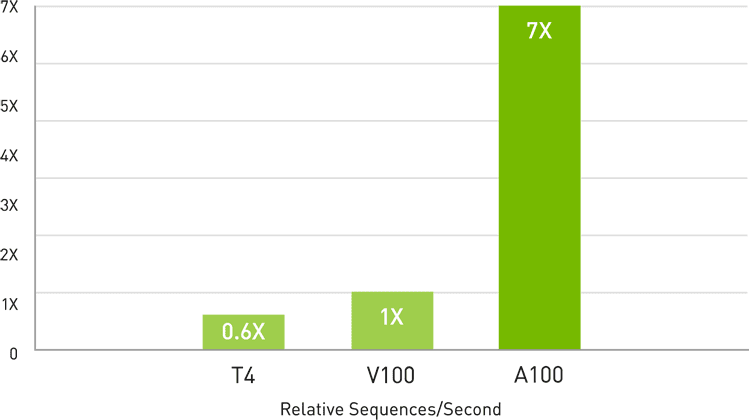
AI推論のためのマルチインスタンスGPU(MIG)により最大7倍高速な性能を実現
BERT Large Inference | NVIDIA T4 Tensor Core GPU: NVIDIA TensorRT™ (TRT) 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 7 MIG instances of 1g.5gb: pre-production TRT, batch size = 94, precision = INT8 with sparsity.
ハイパフォーマンスコンピューティング
A100には倍精度のTensorコアが搭載されています。これにより、NVIDIA V100 TensorコアGPUで10時間を要していた倍精度シミュレーションを、A100でたった4時間に短縮できます。また、HPCアプリケーションではA100のTensorコアでTF32精度を活用し、単精度の密行列積で最大10倍の演算スループットを実現できます。
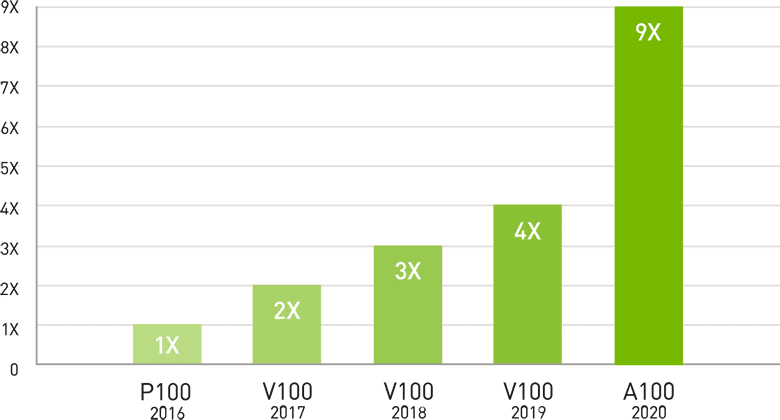
4年間で9倍のHPCパフォーマンス
Geometric mean of application speedups vs. P100: benchmark application: Amber [PME-Cellulose_NVE], Chroma [szscl21_24_128], GROMACS [ADH Dodec], MILC [Apex Medium], NAMD [stmv_nve_cuda], PyTorch (BERT Large Fine Tuner], Quantum Espresso [AUSURF112-jR]; Random Forest FP32 [make_blobs (160000 x 64 : 10)], TensorFlow [ResNet-50], VASP 6 [Si Huge], | GPU node with dual-socket CPUs with 4x NVIDIA P100, V100, or A100 GPUs.
ハイパフォーマンスデータ分析
A100を搭載したアクセラレーテッドサーバーは、要求される計算処理能力のほか、毎秒1.6TB/秒のメモリ帯域幅、第3世代NVLinkとNVSwitchによるスケーラビリティがもたらされ、大規模なワークロードに取り組むことができます。Mellanox InfiniBand、Magnum IO SDK、GPU対応Spark 3.0、GPU活用データ分析用のソフトウェアスイートであるRAPIDS™との組み合わせにより、NVIDIAデータセンタープラットフォームは、画期的なレベルの比類なきパフォーマンスと効率で非常に大規模なワークロードを加速することができます。
企業で効率的に利用
A100とMIGの組み合わせにより、GPU対応インフラストラクチャを今までにないレベルで最大限に活用できます。MIGによってA100 GPUは最大7つの独立したインスタンスに分割でき、複数のユーザーが自分のアプリケーションや開発プロジェクトをGPUで高速化できます。MIGはKubernetesやコンテナー、ハイパーバイザベースのサーバー仮想化によるNVIDIA Virtual Compute Server(vCS)と連携します。MIGを使用することで、インフラ管理者は各ジョブのサービス品質(QoS)を保証した適切なサイズのGPUを提供し、使用率を最適化し、高速化されたコンピューティングリソースの範囲をすべてのユーザーに拡大することができます。
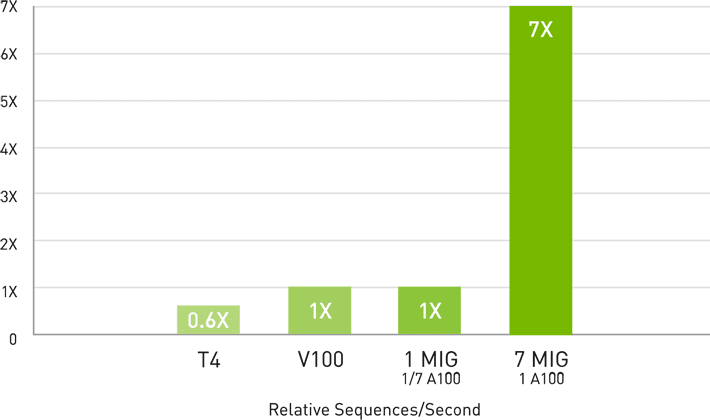
マルチインスタンスGPU(MIG)による7倍の推論スループット
BERT Large Inference | NVIDIA TensorRT™ (TRT) 7.1 | NVIDIA T4 Tensor Core GPU: TRT 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 1 or 7 MIG instances of 1g.5gb: batch size = 94, precision = INT8 with sparsity.
製品概要
| 製品名 | NVIDIA A100 | NVIDIA A100 80GB |
|---|---|---|
| 搭載GPU | NVIDIA A100 | |
| 倍精度演算性能 | FP64:9.7TFlops FP64 Tensorコア:19.5TFlops |
|
| 単精度演算性能 | FP32:19.5TFlops TF32 Tensorコア:156TFlops(sparsity有効時:312TFlops) |
|
| 半精度演算性能 | FP16 Tensorコア:312TFlops(sparsity有効時:624TFlops) | |
| BFloat16 | BFloat16 Tensorコア:312TFlops(sparsity有効時:624TFlops) | |
| 整数演算性能 | INT8 Tensorコア:624TFlops(sparsity有効時:1,248TFlops) INT4 Tensorコア:1,248TFlops(sparsity有効時:2,496TFlops) |
|
| メモリ | 40GB HBM2 | 80GB HBM2e |
| バスインターフェース | PCI Express 4.0 64GB/s(NVLink有効時:600GB/s) | |
| マルチインスタンスGPU(MIG) | 最大7GPU | |
| 消費電力 | 最大250W | 最大300W |
| 型番 | ETSA100-40GER | ETSA100-80GER |
| JANコード | 4524076071000 | 4524076071253 |
| アスクコード | VD7376 | VD7800 |
| 発売時期 | 2020年 10月上旬予定 | 2021年 10月下旬 |
※ 記載された製品名、社名等は各社の商標または登録商標です。
※ 仕様、外観など改良のため、予告なく変更する場合があります。
※ 製品に付属・対応する各種ソフトウェアがある場合、予告なく提供を終了することがあります。提供が終了された各種ソフトウェアについての問い合わせにはお応えできない場合がありますので予めご了承ください。
オプション製品のご紹介
NVLink Bridge 2-Slot(for Ampere)
型番:P3411
JANコード:4524076030304
アスクコード:CB1987

- 株式会社 エルザジャパン 概要
- 1997年の設立以来20年以上にわたり一貫してPC向けのプロフェッショナル/コンシューマ向けGPU搭載グラフィックスボードをはじめとしたビジュアリゼーション関連製品の販売を手掛け、近年ではGPUが持つ卓越した演算能力を生かしたビッグデータ解析やAI、機械学習分野のサーバー機器および高性能ワークステーション、VTuberに代表されるストリーマー向けPC、業務用のハイエンドXR向けHMDにも注力しています。
- メーカーウェブサイト:https://www.elsa-jp.co.jp/
製品に関するご質問や納期のご確認、お見積り依頼など、お気軽にお問い合わせください
お問い合わせはこちら







